Paxos、Multi-Paxos详解
从 Basic Paxos 到 Multi-Paxos
前言
看Paxos视频,很详细的了解了Paxos算法和Multi-Paxos的实现,这篇博客是学习笔记
目标:复制日志
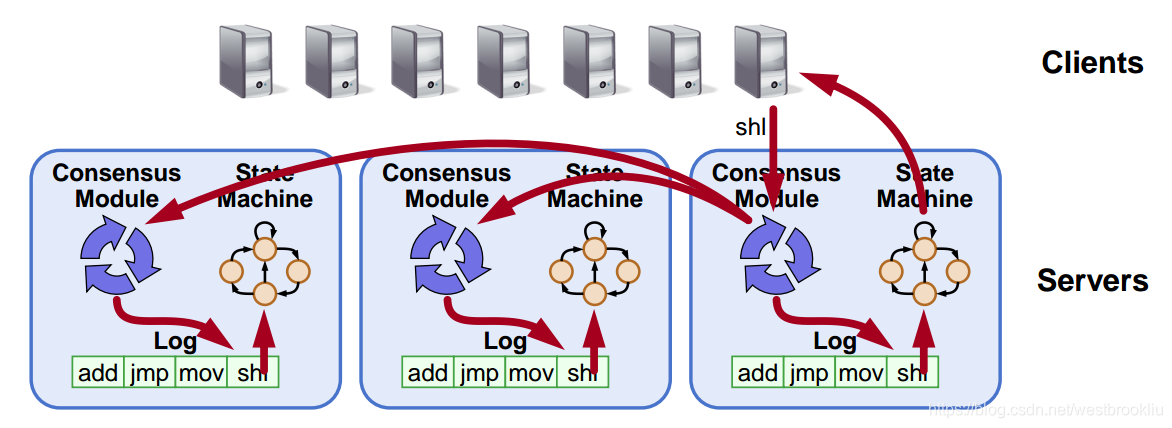 + 复制日志 => 复制状态机
+ 所有服务器按照相同的顺序执行相同的命令
+ 一致性模型确保正确的日志复制
+ 只要大部分服务器是运行的系统就能工作
+ 失败的模型:失败-停止(非拜占庭),延迟/丢失信息
+ 复制日志 => 复制状态机
+ 所有服务器按照相同的顺序执行相同的命令
+ 一致性模型确保正确的日志复制
+ 只要大部分服务器是运行的系统就能工作
+ 失败的模型:失败-停止(非拜占庭),延迟/丢失信息
Basic Paxos
- Proposers:
- 活动的:提出特定的值被选中
- 处理客户请求
- Acceptors:
- 被动的:响应消息给proposers
- 回应达成共识的投票
- 保存选中的值
- 想知道哪个值被选中
- 每个服务器都包含proposer和acceptor
一个Acceptor
 + Q:如果acceptor挂掉了怎么办?
+ A:多个acceptors,选中被大多数acceptors的值
+ Q:如果acceptor挂掉了怎么办?
+ A:多个acceptors,选中被大多数acceptors的值
问题:平分投票
 + Q:Acceptor只接受第一个到达的值?
+ A:如果同时提出提案,不会选中任何值,所以Acceptors必须可以选择多个不同的值
+ Q:Acceptor只接受第一个到达的值?
+ A:如果同时提出提案,不会选中任何值,所以Acceptors必须可以选择多个不同的值
问题:选择冲突
- Q:Acceptor接受所有到达的值?
- A:可能会导致选择多个值(如下图中的S3),所以一旦一个值被选中,以后的提案必须提出/选择一样的值(两阶段提交)

仍然有选择冲突
下图的流程:
1. s1看到此时其他服务器没有接受某个值,之后提出red值
2. s5当时也看到此时没有其他服务器没有接受某个值,就提出blue值
3. blue很快就被s3、s4、s5接受,而s3之后也会接受red值
 + s1的提案必须被终止(s3必须拒绝它)
+ 因此提案必须有序,拒绝旧的提案
+ s1的提案必须被终止(s3必须拒绝它)
+ 因此提案必须有序,拒绝旧的提案
提案值
- 每个提案有一个唯一的值
- 大的优先级高
- 提案者必须选择一个比之前见过的还大的提案值
- 一个简单的方法:
- 一个提案值包括 轮值+服务器ID
- 每个服务器保存 maxRound
- 为产生一个新的提案值:
- 递增 maxRound
- 与服务器ID关联
- 提案者必须将 maxRound 持久化到磁盘,防止提案值在机器宕机重启后重用
两阶段方法
- 阶段一:Prepare RPCs
- 找到已经被选中的值
- 阻止旧的提案
- 阶段二:Accept RPCs
- 请求acceptors接受值
流程

例子
在之后提出一个提案有三种可能:
1. 之前的值已经被选中了
+ 新的Proposer会发现它并使用它
 + 先说明一下方框内写的是什么意思,P表示Prepare,A表示Accept,
3.1中的3表示 Round Number,1表示由s1提出,X为acceptedValue
+ 可以看到之后的提案了解到X已经被选中,s3、s4、s5也会选中同样的值
+ 先说明一下方框内写的是什么意思,P表示Prepare,A表示Accept,
3.1中的3表示 Round Number,1表示由s1提出,X为acceptedValue
+ 可以看到之后的提案了解到X已经被选中,s3、s4、s5也会选中同样的值
之前没有值被选中,但已经被接受
- 新的Proposer会发现它并使用它
- 与前一种情况类似

之前没有值被选中,也没看到值被接受
- 后来的Proposer会使用自己的值
- 旧的值会被拒绝

活锁

其它
- 只有 proposer 知道哪个值被选中了,acceptor是不知道的
- 如果其它服务器想知道,就必须运行paxos
Multi-Paxos
- 用日志项将 Basic Paxos 分成每一轮
- 添加 index 参数到 Prepare 和 Accept

- 添加 index 参数到 Prepare 和 Accept
概述
- 怎么选择哪个日志项来存放给定的客户请求?
- 性能优化:
- 使用 leader 减少 proposer 冲突
- 消除大部分 Prepare 请求
- 复制的完整型
- 客户协议
- 配置变更
选择日志项
- 当客户传来请求:
- 找到第一个没有被选中的日志项
- 运行 Basic Paxos,在这个 index, propose 客户命令
- Prepare 返回 acceptedValue?
- Yes,结束选中 acceptedValue
- No,选中客户命令

当接收到请求时,服务器 S1 上的记录可能处于不同的状态,服务器知道有些记录已经被选定(1-mov,2-add,6-ret),在后面我会介绍服务器是如何知道这些记录已经被选定的。服务器上也有一些其他的记录(3-cmp),但此时它还不知道这条记录已经被选定。在这个例子中,我们可以看到,实际上记录(3-cmp)已经被选定了,因为在服务器 S3 上也有相同的记录,只是 S1 和 S3 还不知道。还有空白记录(4-,5-)没有接受任何值,不过其他服务器上相应的记录可能已经有值了。
当 jmp 请求到达 S1 后,它会找到第一个没有被选定的记录(3-cmp),然后它会试图让 jmp 作为该记录的选定值。为了让这个例子更具体一些,我们假设服务器 S3 已经下线。所以 Paxos 协议在服务器 S1 和 S2 上运行,服务器 S1 会尝试让记录 3 接受 jmp 值,它正好发现记录 3 内已经有值(3-cmp),这时它会结束选择并进行比较,S1 会向 S2 发送接受(3-cmp)的请求,S2 会接受 S1 上已经接受的 3-cmp 并完成选定。这时(3-cmp)变成粗体,不过还没能完成客户端的请求,所以我们返回到第一步,重新进行选择。找到当前还没有被选定的记录(这次是记录 4-),这时 S1 会发现 S2 相应记录上已经存在接受值(4-sub),所以它会再次放弃 jmp ,并将 sub 值作为它 4- 记录的选定值。所以此时 S1 会再次返回到第一步,重新进行选择,当前未被选定的记录是 5- ,这次它会成功的选定 5-jmp ,因为 S1 没有发现其他服务器上有接受值。
注意事项: + 在这种方式下,单个服务器可以同时处理多个客户端请求,也就是说前一个客户端请求会找到记录 3- ,下一个客户端请求就会找到记录 4- ,只要我们为不同的请求使用不同的记录,它们都能以并行的方式独立运行。 + 不过,当进入到状态机后,就必须以一定的顺序来执行命令,命令必须与它们在日志内的顺序一致,也就是说只有当记录 3- 完成执行后,才能执行记录 4- 。
提高效率
- Basic Paxos 是低效的
- 多个 proposers 冲突问题
- 对于选中一个值需要两轮RPCs(Prepare、Accept)
- 解决:
- 选一个 leader
- 在一个时刻,只有一个 Proposer
- 消除大部分 Prepare RPCs
- 一轮 Prepare 完整的日志,而不是单条记录。
- 一旦完成了 Prepare,它就可以通过 Accept 请求,同时创建多条记录。这样就不需要多次使用 Prepare 阶段。这样就能减少一半的 RPCs。
- 选一个 leader
领导选举
选举领导者的方式有很多,这里只介绍一种由 Leslie Lamport 建议的简单方式。
- 让有 最高 ID 的服务器作为领导者
- 可以通过每个服务器定期(每 T ms)向其他服务器 发送心跳消息 的方式来实现。这些消息包含发送服务器的 ID
- 如果它们没有能收到某一具有高 ID 的服务器的心跳消息,这个间隔(通常是 2T ms)需要设置的足够长,让消息有足够的通信传递时间。所以,如果这些服务器没有能接收到高 ID 的服务器消息,然后它们会自己选举成为领导者。
- 也就是说,首先它会从客户端接受到请求,其次在 Paxos 协议中,它会 同时扮演 proposer 和 acceptor
- 如果机器能够接收到来自高 ID 的服务器的心跳消息,它就不会作为 leader,如果它接收到客户端的请求,那么它会 拒绝 这个请求,并告知客户端与 leader 进行通信。
- 非 leader 服务器不会作为 proposer,只会作为 acceptor
- 这个机制的优势在于,它不太可能出现两个 leader 同时工作的情况,即使这样,如果出现了两个 leader,Paxos 协议还是能正常工作,只是不是那么高效而已。
- 应该注意的是,实际上大多数系统都不会采用这种选举方式,它们会采用基于 租约 的方式(lease based approach),这比上述介绍的机制要复杂的多,不过也有其优势。
减少 Prepare 的 RPC 请求
- 为什么需要 Prepare?
- 需要使用提议序号来 阻止 旧的提议
- 使用 Prepare 阶段来检查已经被接受的值,这样就可以使用这些值来替代原本自己希望接受的值。
第一个问题是阻止所有的提议,我们可以通过改变提议序号的含义来解决这个问题, 将提议序号全局化,代表完整的日志 ,而不是为每个日志记录都保留独立的提议序号。这么做要求我们在完成一轮准备请求后,当然我们知道这样做会锁住整个日志,所以后续的日志记录不需要其他的准备请求。
第二个问题有点讨巧。因为在不同接受者的不同日志记录里有很多接受值,为了处理这些值,我们扩展了准备请求的返回信息。和之前一样,准备请求仍然返回 acceptor 所接受的最高 ID 的提议,它只对当前记录这么做,不过除了这个, acceptor 会查看当前请求的后续日志记录,如果后续的日志里没有接受值 ,它还会返回这些记录的标志位 noMoreAccepted 。
使用了这种领导者选举的机制,领导者会达到一个状态,每个 acceptor 都返回 noMoreAccepted ,领导者知道所有它已接受的记录。所以一旦达到这个状态,对于单个 acceptor 我们不需要再向这些 acceptor 发送准备请求,因为它们已经知道了日志的状态。
不仅如此,一旦从集群 大多数 acceptor 那获得 noMoreAccepted 返回值 ,我们就 不需要发送准备的 RPC 请求 。也就是说, leader 可以简单地发送 Accept 请求,只需要一轮的 RPC 请求。这个过程会一直执行下去,唯一能改变的就是有其他的服务器被选举成了 leader ,当前 leader 的 Accept 请求会被拒绝,整个过程会重新开始。
复制的完整性
- 之前的复制是不完整的
- 日志项只需要复制到大多数,我们需要复制到 全部
- 只有 proposer 知道某个日志项被选中了,我们需要所有服务器都知道哪些日志项被选中了
解决办法:
- 在后台持续尝试 Accept RPCs 直到所有 acceptors 返回
- 追踪被选中的日志项
- 让acceptedProposal[i] = 无穷大,这样这个日志项就不可以被覆盖,也就是说被选中了
- 每个服务器还会保持一个 firstUnchosenIndex:表示未被标识选定的最小下标值
- proposer 告诉 acceptors 已经被选中的日志项
- Proposer 在 Accept RPCs 中包含它的 firstUnchosenIndex
- Acceptor 将选中第i个日志项,如果:
- i < request.firstUnchosenIndex
- acceptedProposal[i] == request.proposal
- 结果:acceptors知道大多数被选中的日志项

该 acceptor 在 accept 之前的第6个日志项的提议序号为 3.4 , 这时它收到一个提议序号也为 3.4 的 accepte 请求,并且 请求的 firstUnchosenIndex = 7,大于之前 3.4 所在的 6,所以将选中第6个日志项,同时该请求的 index = 8,将 3.4 的请求放到第8个日志项
这个机制无法解决所有的问题。问题在于 acceptor 可能会接收到来自于不同 proposer 的某些日志记录,这里记录 4 可能来自于之前轮次的服务器 S5 ,不幸的是这种情况下, acceptor 是无法知道该记录是否已被选定。它也可能是一个已失效过时的值。
我们知道它已经被 proposer 选定,但是它可能应该被另外一个值所取代。所以还需要多做一步。
- 旧 leader 的日志项
- Acceptor 返回它的 fristUnchosenIndex 在 Accept回答中
- 如果 proposer 的 firstUnchosenIndex > acceptor回答的 firstUnchosenIndex(说明 acceptor 中的某些状态不确定),proposer就会在后台发送 Success RPC
- Success(index, v):通知 acceptor 该日志项被选中了
- acceptedValue[index] = v
- acceptedProposal[index] = 无穷大
- return firstUnchosenIndex
- 如果需要(可能存在多个不确定的状态),Proposer 发送额外的Success RPC
客户端协议
- 发送命令给 leader
- 如果不知道哪个是 leader,随便选择一个服务器
- 如果该服务不是 leader,重定向 给 leader
- leader 直到日志项被选中并且被 leader 的状态机执行才回应客户
- 如果请求超时(leader 挂了)
- 客户重新发送命令给其他服务器
- 最终重定向给新 leader
- 给新 leader 重试请求
问题
- 如果 laeder 在执行完命令但在回应之前挂掉
- 该命令不能执行两次
解决:客户端需要为每条命令提供一个 唯一的 id
- 服务器会将该 id 存入日志项中
- 状态机会记录每个客户最近执行的命令,即 最高 id 序号
- 在执行命令之前,状态机会检查该命令如否被执行过,如果执行过:
- 忽略
- 返回之前执行的结果
结果:只要客户端不崩溃,就能获得 exactly once 的保证,每个客户端命令仅被集群执行一次。如果客户端出现崩溃,就处于 at most once 的情况,也就是说客户端的命令可能执行,也可能没有执行。但是如果客户端是活着的,这些命令只会执行一次
配置变更
同一时刻不可以出现两个不重叠的多数派

解决办法:
- Leslie Lamport 建议的 Paxos 配置变更方案是用 日志 来管理这些变更,当前的配置作为日志的一条记录存储,并与其他的日志记录一同被复制同步。
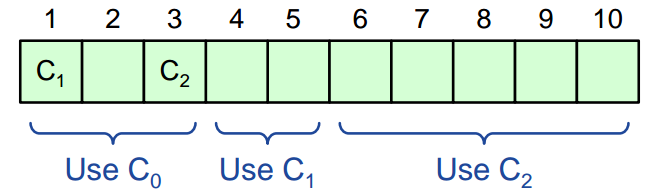
- 所以下图中 1-C1、3-C2 表示两个配置信息,其他的用来存储普通的命令。这里有趣的是,配置所使用每条记录是由它的更早的记录所决定的。
- 这里有一个系统参数 å 来决定这个更早是多早,假设 å 为 3,我们这里有两个配置相关的记录,C1 存于记录 1 中,C2 存于记录 3 中,这也意味着 C1 在 3 条记录内不会生效,也就是说,C1 从记录 4 开始才会生效。C2 从记录 6 开始才会生效。所以当我们选择记录 1、2、3 时,生效的配置会是 C1 之前的那条配置,这里我们将其标记为 C0 。
- 这里的 å 是在系统启动时配置好的参数,这个参数可以用来限制同时使用的配置信息,也就是说,我们是无法在 i+å 之前选择使用记录 i 中的配置的。因为我们无法知道哪些服务器使用哪些配置,也无法知道大多数所代表的服务器数量。所以如果 å 的值很小时,整个过程是序列化的,每条记录选择的配置都是不同的,如果 å 为 3 ,也就意味着同时有三条记录可以使用相同的配置,如果 å 大很多时,事情会变得更复杂,我们需要长时间的等待,让新的配置生效。也就是说如果 å 的值是 1000 时,我们需要在 1000 个记录之后才能等到这个配置生效。
总结
- Basic Paxos:
- Prepare 阶段
- Acceptor 阶段
- Multi-Paxos:
- Choosing log entries
- Leader election
- Eliminting most Prepare requests
- Full infomation propagation
- 客户协议
- 配置变更

