Raft详解
从 Basic Paxos 到 Multi-Paxos
目标:日志复制
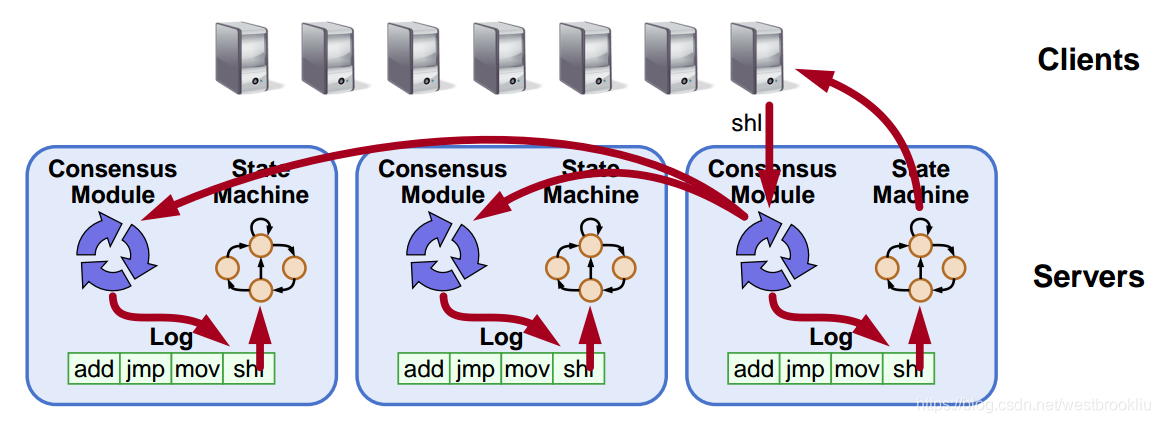
- 日志复制 => 复制状态机
- 所有服务器以一样的顺序执行一样的命令
- 一致性模型确保合理的日志复制
- 只要大多数服务器能运行,系统就能服务
- 失败模型:失败-停止(非拜占庭)、延迟/丢失消息
达成一致性的方法
两种方法: + 对等的,leader-less: + 所有服务器扮演同样的角色 + 客户可以与任意一个联系 + 非对等的,leader-based: + 在任意给定的时刻,只有一个服务器管理,其他服务器接收它的决定 + 客户和leader联系 + Raft使用一个leader: + 分解问题(正常运行,leader变更) + 简化正常操作(没有冲突) + 比leader-less方法更有效
Raft概要
- 领导人选举
- 选择其中一个服务器作为 leader
- 检测服务器宕机,选举新的 leader
- 正常运行(基本的日志复制)
- 领导人选举之后的安全性和一致性
- 淘汰老的 leader
- 客户交互
- 实现线性语义
- 配置变更
- 添加和移除服务器
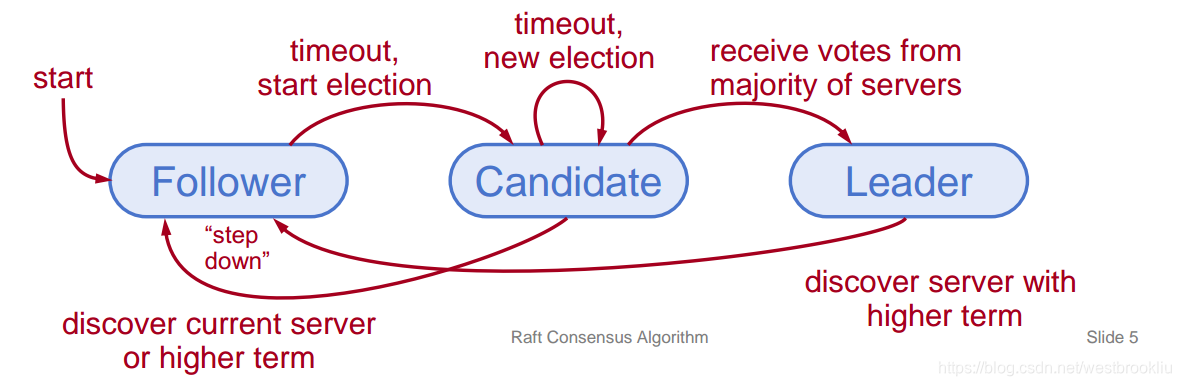
服务器状态
- 在任意时刻,每个服务器只能是以下三种状态之一:
- Leader:处理客户端的所有交互,日志复制
- 一个时刻最多只有一个
- Floower:完全被动(不可以发送任何RPCs,只能回应到达的RPCs)
- Candidate:用来选举出一个新 leader
- Leader:处理客户端的所有交互,日志复制
- 正常运行:1个 leader,N-1个followes
Terms
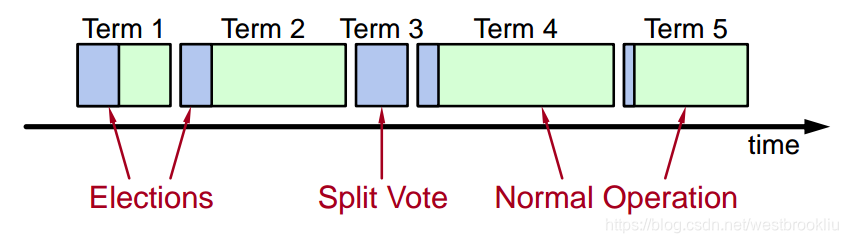
- 时间分成 terms:
- 选举
- 在一个 leader 下正常运行
- 每个 term 最多只有一个 leader
- 有些 term 可能没有 leader (选举失败:比如刚好每个服务器都同时变成了 candidate)
- 每个服务器保持 current term 的值
- terms 的作用:识别过期的信息
心跳和超时
- 服务器开始都是 followers
- followers 都希望能收到从 leaders 或 candidate 发来的RPCs
- leaders 必须发送心跳(空的 AppendEntries RPCs)来保持威信
- 如果没收到RPCs导致选举超时了:
- follower 认为 leader 已经宕机了
- follower 开始新的选举
- 超时时间一般在 100-500ms
选举
- current term + 1
- 变为 candidate
- 给自己投票
- 发送 RequestVote RPCs 给所有其他服务器,如果没收到回应,重传直到回应,之后可能会有三种情况:
- 从大多数服务器收到投票
- 变为 leader
- 发送 AppendEntries 心跳给所有其他服务器
- 收到一个 leader 的RPCs
- 立刻变为 follower
- 没有人赢得选举
- term + 1,重新选举
- 从大多数服务器收到投票
选举特性
- 安全性:每个 term 只允许最多一个服务器赢得选举
- 每个服务器在每个 term 只能投一票
- 两个不同的 candidates 不可能同时取得大多数的选票
- 活性:candidate 最终会赢得选举
- 选举超时时间选择在[T, 2T]间的一个随机值
- 如果T >> 广播时间会工作的很好
日志结构
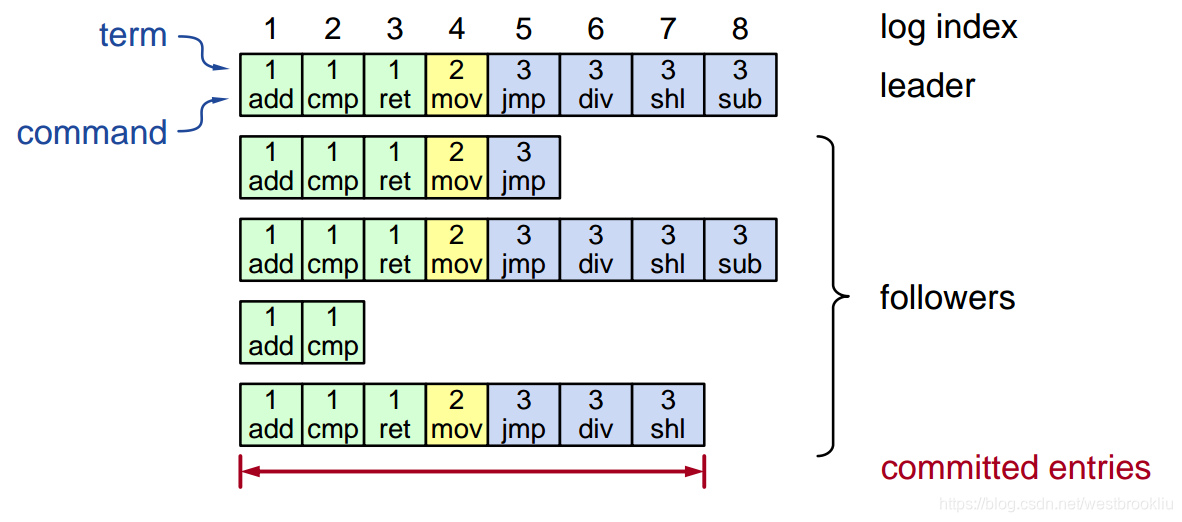
- 日志项 = index,term,command
- 日志存储在磁盘上
- 如果日志项已经存储在大多数服务器上,则该日志项是 committed
正常运行
- 客户发送命令给 leader
- leader 添加命令到它自己的日志中
- leader 发送 AppendEntries RPCs 给 followers
- 一旦新的日志 committed
- leader 在它的状态机上执行该命令,返回结果给客户
- leader 会在后续的 AppendEntries RPCs 中通知 followers 已经 committed 的日志项
- followers 在它们的状态机上执行已经 committed 的命令
- 挂掉或落后很多的 followers?
- leader 重发 RPCs 直到成功
- 在正常情况下性能很好:
- 只需给大多数服务器一个成功的 RPC
日志一致性
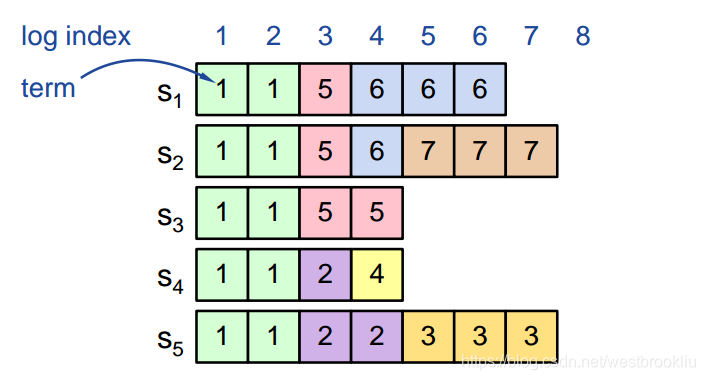
- 如果不同服务器上的某个日志项有着相同的 index 和 term(下图的第5项):
- 它们存储着相同的命令
- 而且该日志项之前的所有日志都相同

- 如果给定日志项已经 committed,那么该日志项之前所有的日志项也都 committed
AppendEntries 一致性检查
- 每个 AppendEntries RPC 包含最新的日志项之前一项的 index,term (如下图的第4项)
- follower 必须包含一样的日志项,否则拒绝请求
- 下图的上半部分能对应的上,所以成功
- 下图的下半部分没匹配上,所以失败

Leader 变更
- 在新 leader 的 term:
- 老 leader 可能会留下只复制了部分的日志项
- 没有什么特殊的步骤,只需要正常运行
- leader 的日志就是正确的
- 最终都会让 follower 的日志和 leader 一样
- 多个服务器宕机可能会导致很多没用的日志项
下图的S4和S5发生了网络分区
安全性的要求
一旦一个日志项已经应用到状态机中,别的状态机不会应用一个不同的值到该日执行中 + Raft 安全特性: + 如果一个 leader 已经决定一个日志项 committed,那么该日志项就会出现在未来的 leader 的日志中 + 这保证了安全性的要求 + leaders 不会覆盖自己的日志 + 只有 leader 的日志才能 committed + 日志项必须 committed 在应用到状态机之前
选择一个最好的 leader
下图中的第5项是无法确定是否已经 committed
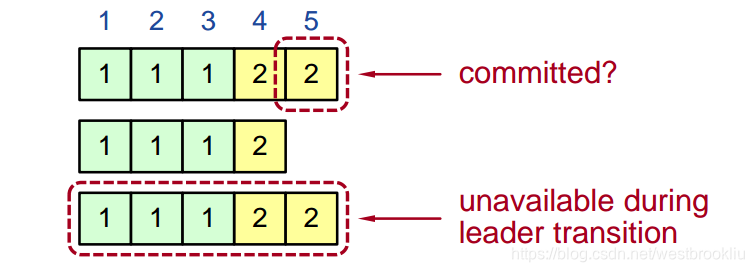
在选举期间,选择最有可能包含全部已经 committed 日志的 candidate
- candidate 会在 RequestVote RPCs 中包含日志信息(index & 最后一个日志项的 term)
- 投票给拥有最完整的日志的 candidate:
- (lastTermV > lastTermC) || (lastTermV == lastTermC) && (lastIndexV > lastIndexC)
- leader 将会在拥有最完整日志的 candidate 中选出来
在当前 term commiting 日志项
- leader 决定在当前 term 的日志项 committed

- 看上图,term3 的 leader必须包含第4项日志
Commiting 之前 term 的日志项
- leader 会尝试完成 commiting 之前 term 的日志项
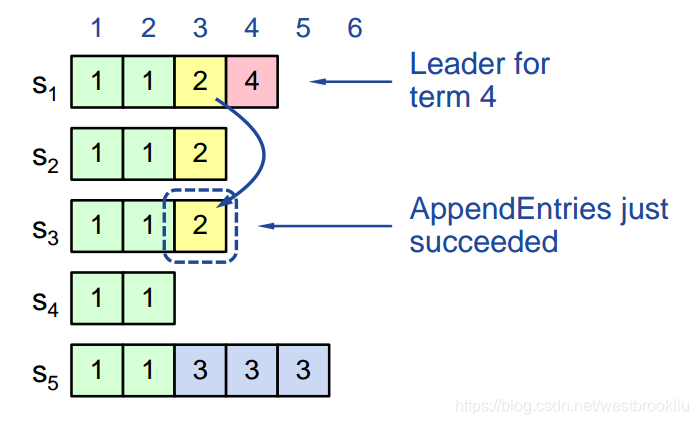
- 第3项日志不会安全地 committed:
- s5可以被选举为 term5 的 leader
- 如果s5称为 leader,它将覆盖在s1、s2、s3的第3项日志
新的 commitment 规则
leader 决定一个日志项是否 committed:
- 必须已经存储在大部分的服务器上
- 最少一个新的日志项在该 leader 的 term 已经存储在大部分
- 如下图中的 term4 的 leader

一旦第4项日志 committed:
- s5就不能被选为 leader
- 第3项和第4项日志就安全了
日志不一致
- leader 变更会导致日志的不一致:
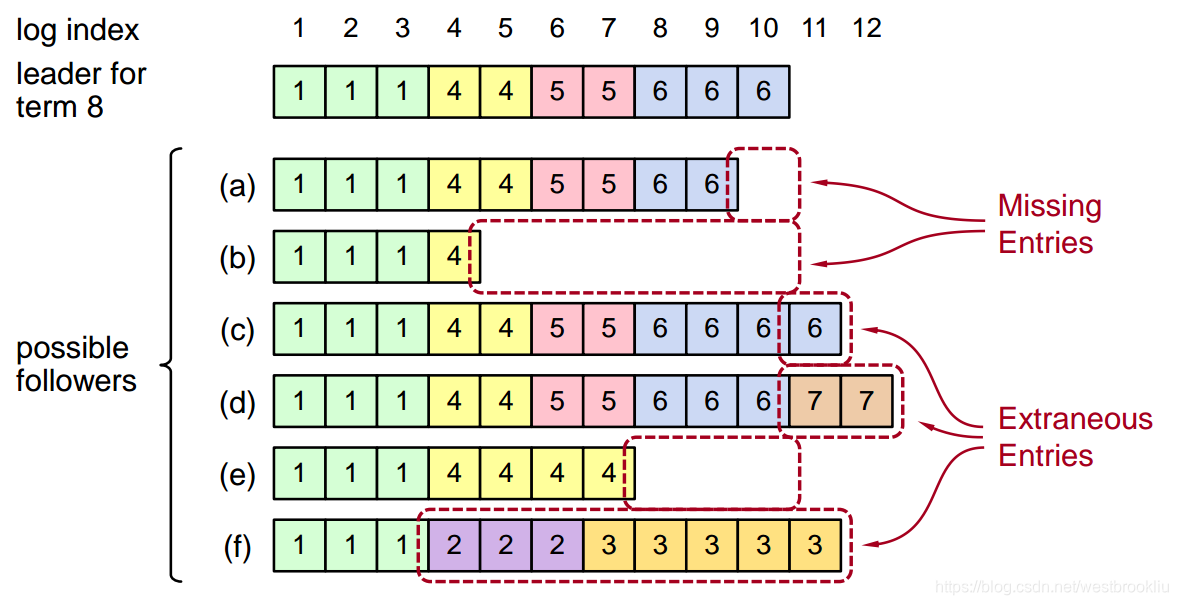
复原 follower 的日志
- 新 leader 必须让 follower 的日志与它自己的保持一致
- 删掉多余的日志
- 补充丢失的日志
- leader 为其他 follower 持有一个变量 nextIndex:
- 发送给该 follower 的下一个日志项的 index
- 初始化为 (1 + leader 的 最后一个 index)
- 当 AppendEntries 一致性检查失败了,减小 nextIndex 然后重试

老 leader
- 老 leader 可能并没有宕机
- 只是暂时断开网络
- 其它服务器选出了一个新的 leader
- 老 leader 重新连接上,想要 commit 日志项
- Terms 被用来检测过期的 leader(和 candidate)
- 每个 RPC 的发送者都会包含它自己的 term
- 如果发送者的 term 是老的,RPC 就会被拒绝,发送者变为 follower 并且更新自己的 term
- 如果接收者的 term 是老的,接收者就变为 follower,并且更新自己的 term,然后正常执行 RPC
- 选举会更新大部分服务器的 term
- 老的 leader 就不可以 commit 新的日志项
客户协议
- 发送命令给 leader
- 如果不知道哪个是 leader,随便联系一个服务器
- 如果联系的不是 leader,该服务器会重定向给 leader
- leader 不会回应直到命令已经 committed,并且已经在 leader 的状态机中执行了
- 如果请求超时(如 leader宕机):
- 客户重新发命令给其它服务器
- 最终会给到新的 leader
- 在新 leader 会重试该请求
客户协议的问题
- 如果 leader 在执行命令之后宕机了,但还没有回应客户
- 不可以执行两次命令
- 解决办法:客户给每个命令一个唯一的id
- 服务器将该 id 包含到日志项中
- 在接受命令请求时,leader 先检查它的日志又没有相同的id
- 如果有,忽略,返回老命令的结果
- 结果:只要客户没有宕机就可以实现只有一次语义
配置变更
- 系统配置:
- ID,每个服务器的地址
- 大多数的数目
- 一致性机制必须支持配置变更:
- 替换坏的机器
- 改变复制的数目
配置变更的问题
不可以直接从一个配置到另一个配置:大多数的数目会冲突

共同一致性
- Raft 采用 2-phase 方法:
- 中间阶段采用共同一致性(需要老和新的配置的大多数来选举和提交)
- 配置变更就是一个日志项;无论有没有 committed 都会立即应用
- 一旦 共同一致性的日志项 committed,开始为最后的配置复制日志
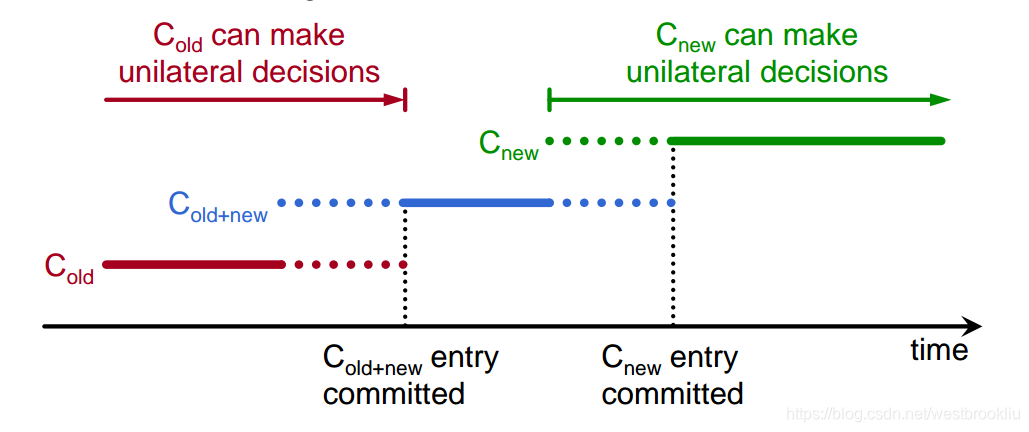
共同一致性的问题
- 在任何一个配置下的任何服务器都可以充当 leader
- 如果当前 leader 不在 Cnew 中,一旦 Cnew committed,就变为 follower
总结
- leader 选举
- 正常运行流程
- 安全性和一致性
- 处理老的 leader
- 客户协议
- 配置变更

